November 25th 2017 - Tejpal Virdi
Introduction
The growth of Deep Learning in the last few years has been reliant on an immense amount of computational power and extensive datasets. For example, the annual ImageNet competition decreased image recognition error rates from 28.2% to 6.7% by providing millions of labeled images. However, these datasets are not available for many domains. This blog post analyzes the use of Generative Adversarial Networks (GANs) for developing reliable synthetic training data.
A special feature of GANs is its ability to generate images that no one has seen before. As we saw two posts ago, the generator is not trained on the training images but rather on trying to minimize the loss function of the discriminator. Since the generator never sees the images that the discriminator is trained on, it is not likely for it to produce images that are copies of it (given the training data is varied enough) but instead images of similar structure (learning from the distribution).
Since the produced images have never been seen before, it preserves a valuable characteristic: privacy. Many datasets are not publicly available due to privacy concerns, including: medicine, surveillance, driving, etc; however, these datasets could be reproduced with a GAN. This post looks particularly at generating images, for medical and satellite imaging domains, that are free from privacy concerns.
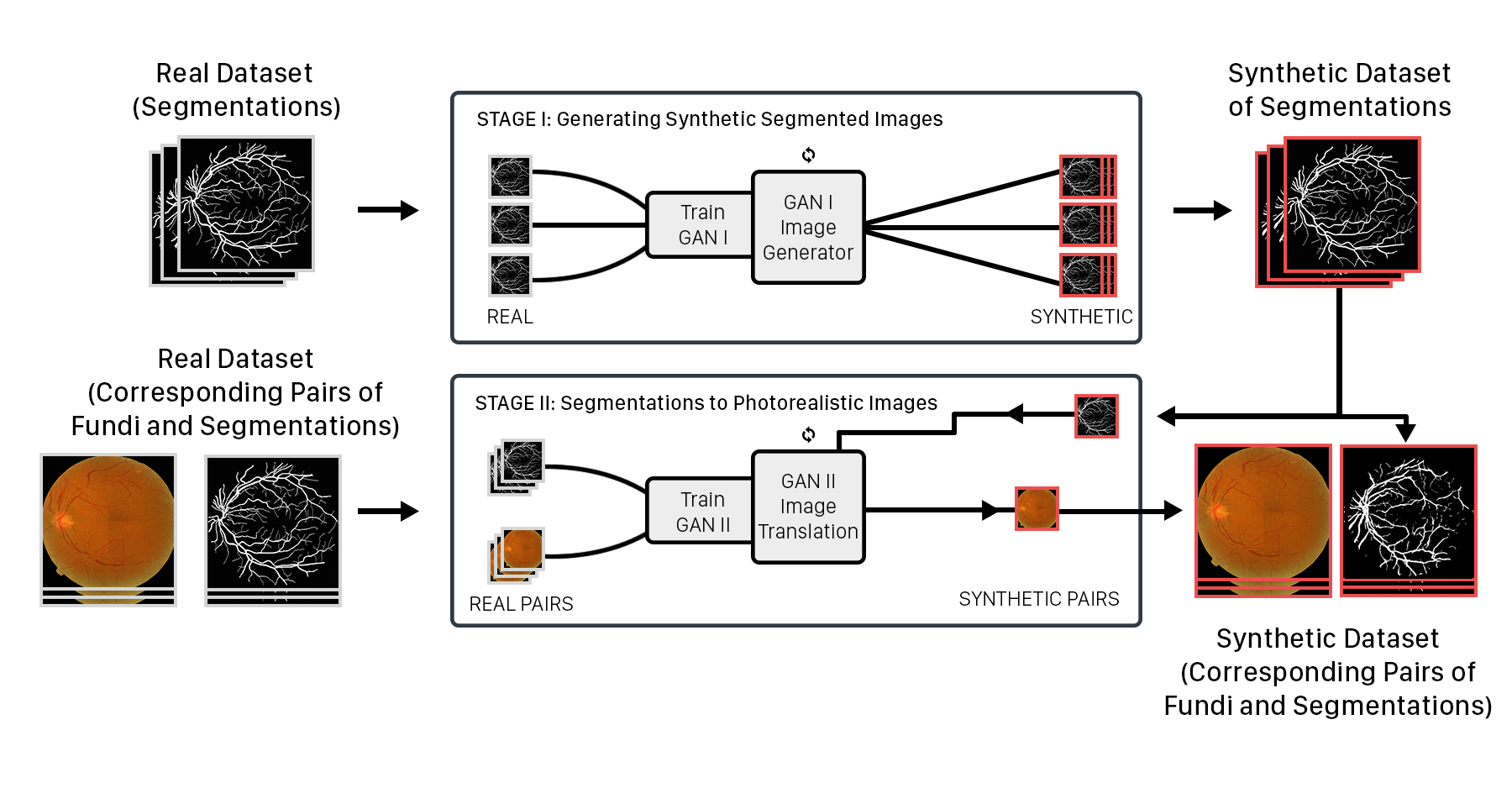
We also explore a dual GAN architecture, in regards of enhancing the output quality. Stacking GANs has shown to produce images that are of higher quality than a single GAN. Zhang et al. showed this by producing a low-quality image from text-to-image synthesis and then employing a conditional GAN to produce a high-quality image given the low-quality image. For example, we could have a situation where the first GAN produces a segmentation while the second GAN produces a photorealistic satellite image given the segmentation.


Applicable Domains
Medical Data is fraught with privacy concerns, meaning that there are various barriers from distributing patient data aside from educational purposes. However, this in turn has hindered the advancement of computer-aided medical diagnosis since deep learning methods are not supported without extensive datasets. Synthetic data, on the other hand, solves this problem by providing sufficient amounts of training data.
Aerial/satellite images are especially difficult to obtain since it is expensive to fly a drone or device to take quality pictures for miles. This limits the publicity of the data since people are not likely to distribute it for free. In addition, there has been controversy on aerial images over residential areas that may obtrude upon privacy.
Another domain that is limited by a lack of public data is security. Surveillance cameras, for example, can be heavily improved with the use of computer vision techniques. Criminals can be easily detected through super-resolution and facial recognition, and computers can easily go through thousands of hours of footage while still being accurate. However, these datasets are not readily available for public research and contribution.
Even when the data is obtained, segmenting it is a tedious and unproductive process for humans. However, these images are extremely useful for creating topographical maps, road planning, disaster mitigation, and much more. Without sufficient data, neural networks are unable to help in these tasks.
Methods
The first step of the pipeline is to generate the segmentation mask. We employ a DCGAN, as described in our image generation blog post. Although better models exist (DRAGAN, BEGAN, WGAN), we used a DCGAN architecture as we were the most comfortable with it. It’s nice for image generation since its depth allows for a hierarchical learning of representations. The depth also results in increased stability and higher quality images. However, the millions of parameters will dramatically increase the computational time.
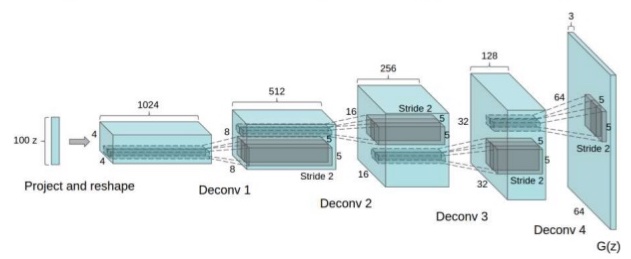
Regarding the specifics, DCGAN differs from a vanilla GAN in the following ways: replacement of pooling layers with strided convolutions, use of batch normalization in both the generator and discriminator, removal of fully-connected layers (network depth compromises input dimensionality), heavy use of ReLU in the generator, and heavy use of Leaky ReLU in the discriminator. We then use the generated mask to condition the mapping from the segmentation to a photorealistic satellite image. The conditional GAN follows the same training process as the normal GAN except it takes in an additional parameter that represents the condition (in our case, the segmentation mask). Here is what it looks like:
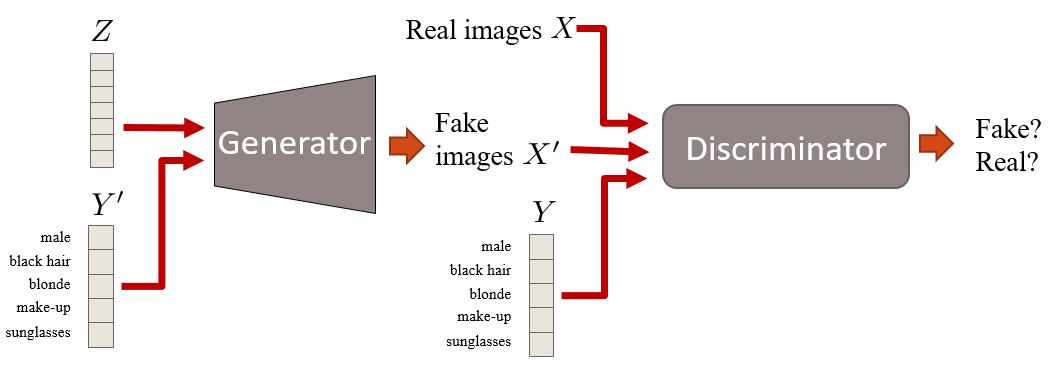
As we saw in the GAN post, the generator and discriminator compete in the minimax game. Here is what it looks like with the additional parameter y:
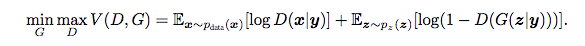
Finally, here is what our final architecture looks like:
Results
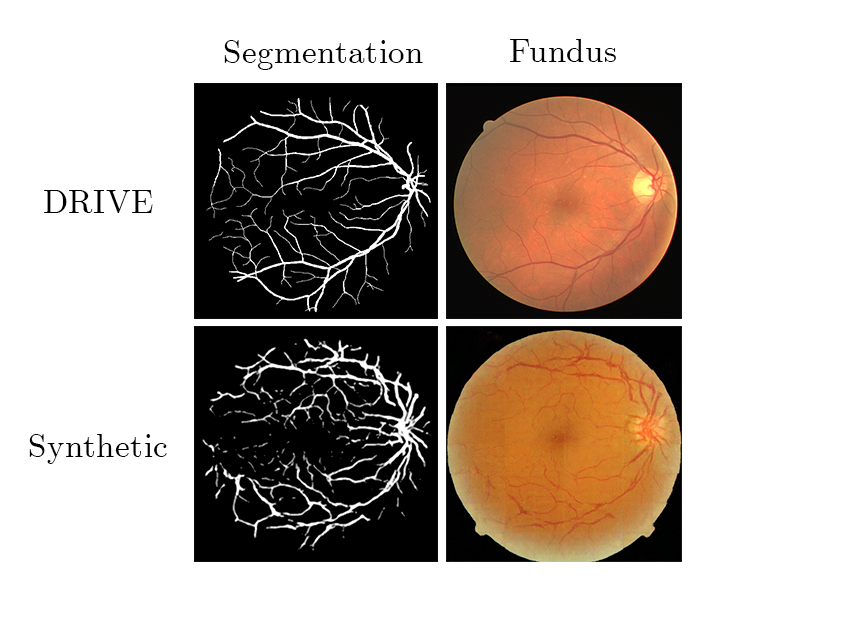
Here are some results from our experimentation with retina data: