November 15th 2017 - Tejpal Virdi
Introduction
Style transfer involves takes a style image representing style and a content image and outputting an image that has the style of the first and the content of the second. This may seem trivial for human intelligence but is difficult for machine intelligence. However, in August 2015, Gatys et al. showed impressive results with their architecture for style transfer. Most notably, they were able to extract two principal feature sets from an input image: style and content. As we saw in the post on Convolutional Neural Networks, the network identifies certain feature maps after each layer. Specifically, we saw that early layers in the network would learn edges and corners while the layers toward the end of the network would learn high-level features such as an entire outline of an object.
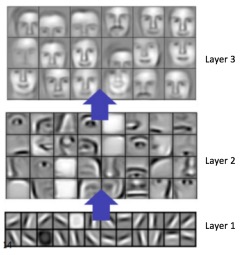
By using a network pre-trained (VGG-19 is commonly used) on a large and varied dataset such as ImageNet, we can simply pass our style and content image through and get accurate depictions of style and content. Specifically, as seen in the figure above, activations of later layers give accurate representations of the content while style can be found in activations from the beginning layers. This is known as reconstruction where we reconstruct a stylized image given a lower representation. These lower representation are forced into the reconstructed image and appear as if the network has learned a semantic representation of the content and style images.
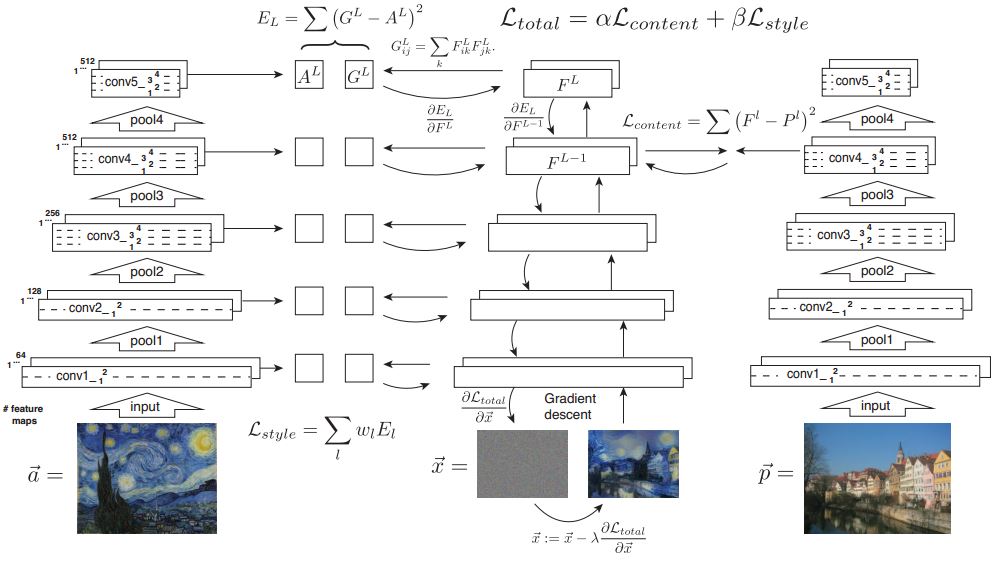
To create an image that contains the style and content, we must incorporate it into the loss function. Meaning, the generated image should minimize loss when comparing to both the style activation and the content activation. Here are some famous examples using the Mona Lisa as a base image:

Mathematically, we want to do the following:
The content image is the feature map at certain early layers after passing our input image through VGG-19. We express a feature map in terms of the input X and a layer C as FXC
Minimizing content loss (mean-squared error):
Minimizing style loss (mean-squared error): The style of an input X at layer C is calculated by multiplying certain vectorized feature maps in a certain interval of the network. Given K feature maps, the output Gram matrix of the multiplication is KxK. This is what we will use as our style image when computing loss.
The interesting part of this new loss function is that instead of doing a per-pixel loss, we are now comparing it to perceptual, higher-level differences.
Real-Time Style Transfer
The approach described above aims to solve an optimization problem by performing gradient descent on the loss defined by both style and content features. However, the training time prevents from real-time application of this technology. On a CPU, a 256x256 image takes ~2 hours. Also, this method requires hyperparameter searching when training. Instead, we can pre-train a network to learn a style and then apply that style to a content image, allowing for real-time style transfer. Similar to what we saw with SRGAN, we will utilize a perceptual loss (Johnson et al.). Perceptual loss is based on comparing outputs to high-level features extracted from pretrained networks, specifically the VGG-19. This loss encourages the network to have similar features rather than exact pixel values to the original image. Although this may not perform well quantitatively, the sharper details from the use of a perceptual loss result in a qualitatively superior output. With this, only a single pass of the content image through our image transformation network is needed to do style transfer.
Code for Style Transfer in PyTorch here